Claude AI for Test Case Generation: 10 Prompts + Model Guide
Use Claude for QA test case generation — 10 copy-paste prompts, Claude vs ChatGPT vs Gemini for testing, model + temperature settings, and a review rubric.
In this article
- Why Claude is useful for QA work
- Safe input rules
- Prompt template for test case generation
- Example: ecommerce coupon prompt
- Use Claude to find missing requirements
- Use Claude for exploratory charters
- Use Claude for API test cases
- Use Claude to improve manual test cases
- Use Claude for test data
- Quality checklist for Claude output
- Claude vs ChatGPT vs Gemini for test case generation
- Which Claude model and settings should QA use?
- 10 copy-paste Claude prompts for QA
- 6-point review rubric for Claude output
- Common mistakes
- Example review workflow for a sprint story
- What good output looks like
- Final thoughts
- Frequently asked questions
Claude can be very useful for test case generation because it handles long context well and produces clear, structured writing. For QA engineers, that means you can use it to review requirements, find missing rules, draft test cases, create exploratory charters, generate test data ideas, and improve test documentation. But the quality of output depends heavily on the quality of your input.
The best way to use Claude is not to ask, "Write test cases." That prompt is too broad. A better prompt explains the feature, user roles, business rules, known risks, supported platforms, data constraints, and the output format. Claude then gives you a draft that is much easier to review and publish into your test management tool.
SoftwareTestPilot tip: Pair this guide with our AI Mock Interview, QA Resume ATS Review, and the companion 50 ChatGPT prompts for testers.
Why Claude is useful for QA work
Claude is helpful when the requirement is long or messy. Many QA teams receive user stories with acceptance criteria, design notes, API details, and comments from several stakeholders. Reading everything and turning it into coverage can take time. Claude can summarize the requirement, list assumptions, identify ambiguity, and create a first version of test cases.
This is especially useful before refinement meetings. Instead of entering the meeting with only a rough understanding, a tester can bring specific questions: What happens if the coupon expires during checkout? Can an admin edit a disabled user? Should the API return 400 or 422 for invalid data? These questions improve quality before development even starts.
Safe input rules
Before using Claude or any AI assistant, follow your company policy. Do not paste production data, access tokens, customer records, private keys, confidential contracts, or sensitive logs. Replace real emails, phone numbers, IDs, and names with dummy values. If your company provides an approved enterprise AI tool, use that instead of a personal account.
A safe prompt can still be useful. You can describe rules without exposing secrets. For example, say "payment provider" instead of naming a confidential integration if needed. Say userId instead of pasting real IDs.
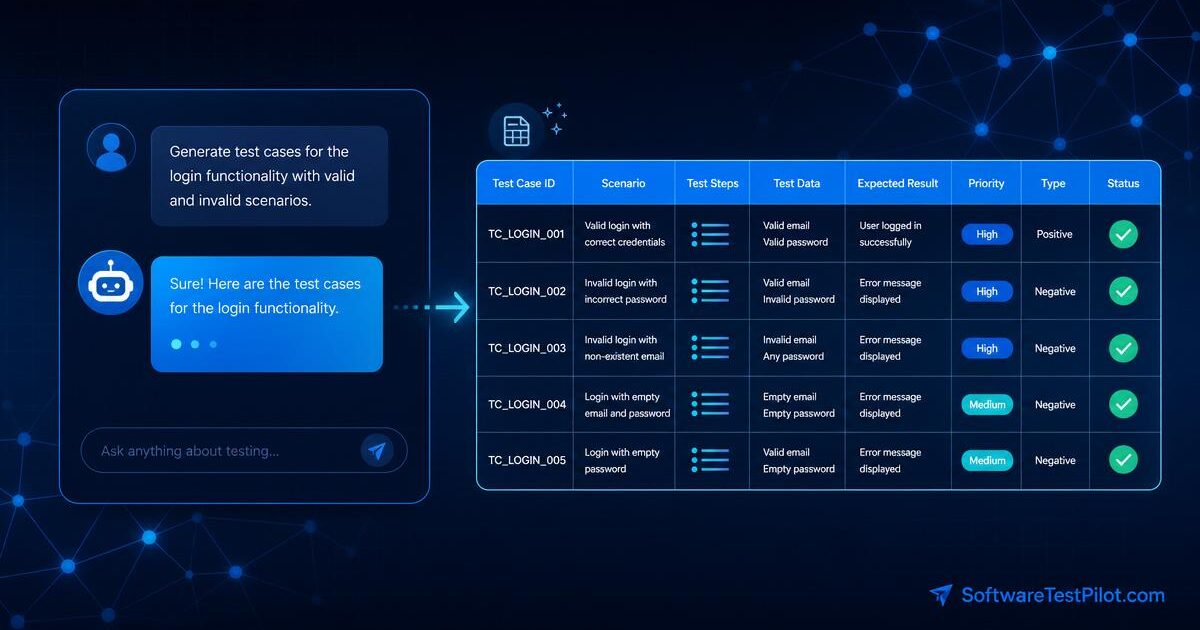
Prompt template for test case generation
Use this template as your default starting point:
Act as a senior QA engineer.
Feature: [describe feature]
User roles: [roles]
Business rules: [rules]
Platforms: [web/mobile/API]
Known risks: [risks]
Out of scope: [items]
Create test cases in a table with ID, scenario, preconditions, steps, test data,
expected result, priority, and type.
Include positive, negative, boundary, security, accessibility, and regression cases.
Also list open questions separately.This prompt tells Claude what role to take, what context matters, and how to structure the answer. It also asks for open questions, which is one of the most valuable outputs.
Example: ecommerce coupon prompt
Act as a senior QA engineer. Generate test cases for an ecommerce coupon feature.
Rules: One coupon per order. Coupon may be percentage or fixed amount. Some coupons
apply only to first-time users. Coupon cannot reduce total below zero. Expired
coupons must show a clear message. Coupons are not valid on gift cards. Users can
remove a coupon before payment.
Create functional, negative, boundary, and regression test cases. Include test data
and expected result.Claude may produce cases for valid coupon, expired coupon, first-time-only coupon, minimum cart value, gift card exclusion, removing coupon, applying coupon twice, and payment retry after discount. You should then add product-specific cases such as tax calculation, shipping discount interaction, wallet payment, and refund behavior.
Use Claude to find missing requirements
Test case generation is useful, but requirement review may be even more valuable. Ask Claude:
Review this requirement as a QA lead. List ambiguity, missing business rules,
risky assumptions, integration questions, test data needs, and edge cases. Do not
create test cases yet.
[paste sanitized requirement]This separates thinking from documentation. If you generate test cases too early, you may create cases based on wrong assumptions. Requirement questions help the team clarify behavior first.
Use Claude for exploratory charters
Manual testers can ask Claude to create exploratory testing charters. A charter is better than a checklist when you want to learn about risk.
Create five exploratory testing charters for a new invoice download feature.
Each charter should have mission, setup, data ideas, risks, notes to capture,
and timebox.This gives testers a practical plan. One charter may focus on permissions, another on file formats, another on large invoice history, another on mobile browser behavior, and another on failure handling.
Use Claude for API test cases
For APIs, provide endpoint, method, authentication, request body, response body, validation rules, and status codes. Ask for schema, boundary, authorization, idempotency, and error tests.
Create API test cases for POST /refunds. Rules: only paid orders can be refunded,
refund amount cannot exceed paid amount, partial refunds are allowed, duplicate
requestId should not create duplicate refunds, support role can initiate refund,
viewer role cannot. Include status codes and sample payloads.Claude can create useful cases, but verify every status code against your API standard. Some teams use 400, some use 422, some use domain-specific error codes. For hands-on API practice, see our API testing interview questions and Postman tutorial.
Use Claude to improve manual test cases
If you already have test cases, ask Claude to review them:
Review these test cases for clarity, duplicate coverage, missing negative cases,
missing expected results, and automation candidates. Suggest improvements in a
table.
[paste sanitized cases]This is helpful when test suites become old and repetitive. Claude can identify unclear steps or missing expected results, but the final decision should come from the QA owner.
Use Claude for test data
Test data is often where bugs hide. Ask for realistic data sets:
Generate test data for a user registration form with name, email, phone, password,
country, and optional referral code. Include valid data, boundary data, Unicode
characters, long values, special characters, duplicate email, and invalid phone
formats.Then adapt the data to your product. If your app supports India, include Indian phone formats, PIN codes, GST rules, or local payment methods where relevant. You can also use our free random test data generator when you need repeatable structured data instead of freeform AI output.
Quality checklist for Claude output
Before you use the output, check whether every case maps to a real rule. Remove generic cases that do not matter. Add cases from production incidents. Confirm expected results with product owners. Mark automation candidates. Check whether high-risk areas have enough coverage. Finally, make the language simple enough for another tester to execute.
AI output becomes valuable only after human review. The final test suite should feel like it came from someone who knows the product.
Claude vs ChatGPT vs Gemini for test case generation
All three can generate test cases. They are not equal for QA work. Here is how they compare on the tasks that matter most for testers.
| Task | Claude 3.5 / 4 Sonnet | ChatGPT (GPT-4.1 / o-series) | Gemini 2.x Pro |
|---|---|---|---|
| Long requirements (20+ pages) | Best — 200K context, keeps rules straight | Good with structured chunks | Good, occasionally drops mid-doc rules |
| Structured test-case tables | Best — consistent columns | Good | Good |
| Edge-case brainstorming | Good | Best — creative negatives | Good |
| API test generation | Very good | Very good | Good |
| Automation code snippets | Very good | Best (via Copilot lineage) | Good |
| Cost per 1M tokens (approx.) | Mid | Mid–High | Low–Mid |
Recommendation: Use Claude when the requirement is long, messy, or spans multiple docs. Use ChatGPT when you want the widest edge-case coverage. Use Gemini when cost or Google Workspace integration matters. Compare with our ChatGPT prompts guide to pick per task.
Which Claude model and settings should QA use?
Model choice matters more than most testers think.
- Claude Sonnet (default): Best price/quality for daily test-case work, bug report rewrites, and log summaries. Start here.
- Claude Opus / 4.x: Use for large PRDs (50+ pages), regulatory rules, or when Sonnet misses subtle constraints. 5–10x cost but sharper on nuance.
- Claude Haiku: Use for high-volume, low-complexity tasks — CI log summarization, mass bug-report reformatting.
Temperature: For test-case generation, use 0.2–0.4. Lower values produce consistent, table-friendly output. Higher values (0.7+) are only useful for exploratory charter brainstorming.
Context strategy: Paste the PRD once, then ask 5 follow-up questions in the same conversation. That preserves context and saves tokens vs. repeating the requirement every time.
10 copy-paste Claude prompts for QA
Save these in a personal snippet manager (Raycast, Alfred, Notion) and adapt them to your product.
- Requirement review: "Act as a QA lead. Review this requirement for ambiguity, missing business rules, edge cases, integration risks, and open questions. Do not write test cases yet."
- Test case table: "Generate test cases in a markdown table with columns ID, scenario, preconditions, steps, data, expected, priority, type. Cover functional, negative, boundary, security, accessibility, regression."
- Risk-based prioritization: "From these 40 test cases, select the 10 highest-risk cases for a 2-hour smoke suite. Justify each choice in one sentence."
- API test cases: "Generate REST API test cases for [endpoint]. Include auth, validation, boundary, idempotency, rate-limit, and error-status assertions."
- Exploratory charter: "Create 5 exploratory charters for [feature]. Each charter: mission, setup, data, risks, notes to capture, 45-min timebox."
- Bug report rewrite: "Rewrite this bug report using: title, environment, steps, expected, actual, severity, screenshots-needed. Keep it under 200 words."
- Test data: "Generate test data for [form] with valid, boundary, Unicode, long, special-char, duplicate, and invalid variants. Return as JSON."
- Log triage: "Group these 50 failed test logs by likely root cause. Return a table with cause, count, confidence, suggested owner."
- Automation review: "Review this Playwright test for flakiness risks (fixed waits, unstable selectors, shared state, weak assertions). Rewrite the risky parts."
- Release summary: "Draft a release QA summary: scope, environments, automation results, manual coverage, open defects by severity, risks, go/no-go recommendation. Plain language."
Pair with the automation examples in our Copilot for Cypress guide.
6-point review rubric for Claude output
Do not ship AI-generated test artifacts without a review pass. Score every output on these six points:
- Rule fidelity: Does each test case tie to a real business rule?
- Data realism: Are inputs realistic for production, not placeholder gibberish?
- Edge coverage: Are boundary and negative cases explicit?
- Executability: Can a new tester run the steps without asking questions?
- Duplication: Are there overlapping cases you can merge?
- Risk alignment: Do the highest-priority cases match known incident history?
If any score drops below 4/5, refine the prompt (add rules, examples, or constraints) and regenerate rather than manually patching the output.
Common mistakes
One mistake is pasting the whole requirement and asking for everything at once. Break the work into steps: summarize, find questions, create risk list, generate cases, review cases. Another mistake is ignoring open questions. If Claude says a rule is unclear, do not guess silently. Ask the product owner.
A third mistake is creating too many test cases. AI can generate 100 cases quickly, but your team may not need 100 manual cases. Use risk-based selection.
Example review workflow for a sprint story
A practical sprint workflow can be simple. On day one, the tester reads the story and asks Claude for ambiguity, missing rules, and risk areas. The tester takes only the useful questions to refinement. After the product owner clarifies behavior, the tester asks Claude for a structured test case draft. The tester then edits the draft, removes low-value cases, and marks automation candidates.
During development, the tester can ask Claude to create test data ideas and API validation checks. During test execution, rough notes can be converted into clear bug reports or a daily QA summary. At the end of the sprint, Claude can help write a concise test closure note.
This workflow keeps the tester in control at every step. Claude is used for acceleration and organization, not for final approval. That distinction matters for quality and for professional growth.
What good output looks like
Good AI-assisted test cases are specific, executable, and tied to rules. They mention preconditions, data, exact expected result, and priority. Weak output is generic: "verify user can submit form" or "check error message." If Claude gives weak output, improve your prompt by adding rules, examples, and constraints. Prompting is an iterative testing skill.
Final thoughts
Claude is a strong QA assistant for test case generation, especially when requirements are detailed. It can help testers think wider and document faster. But it should not replace product understanding or review. Use Claude to prepare, question, draft, and refine. Keep humans responsible for final coverage. For more AI + QA workflows, read How AI is changing QA in 2026 and GitHub Copilot for QA.
Frequently asked questions
Can Claude generate complete test cases?
Yes, it can generate strong drafts, but QA engineers must review and customize them for product-specific rules, real data constraints, and known production incidents.
Is Claude better than ChatGPT for QA?
Both are useful. Claude is often strong with long documents and structured review. ChatGPT is also strong for brainstorming, examples, and quick prompts. Most teams use both.
Can I paste company requirements into Claude?
Only if your company policy allows it. Sanitize sensitive information — remove tokens, customer PII, and confidential integration names — and prefer an approved enterprise AI tool over personal accounts.
What is the best Claude prompt structure for test case generation?
Role, feature, user roles, business rules, platforms, known risks, out-of-scope items, and the exact output format (table columns). Ask for open questions separately from test cases.
Which Claude model should QA engineers start with?
Start with Claude Sonnet — best price/quality for daily QA work. Upgrade to Opus for 50+ page PRDs or regulated features where subtle rules matter. Use Haiku only for high-volume, low-complexity tasks like log summarization.
What temperature setting works best for test case generation?
Use 0.2–0.4 for test case tables and bug report rewrites (consistent, structured output). Bump to 0.7 only for exploratory charter brainstorming when you want more creative variance.
How many test cases should Claude generate per feature?
Ask for 15–25 draft cases per feature, then trim to the 8–12 that actually reduce risk. Volume looks impressive but slows execution — risk-based selection wins every audit.
Can Claude replace a QA engineer?
No. Claude accelerates drafting, review, and documentation. Product judgment, exploratory intuition, and stakeholder communication still require a human. Teams that outsource judgment to AI ship more escaped defects, not fewer.
Practice these questions
Run a live QA mock interview tailored to this topic and get per-skill scoring in minutes.
Was this article helpful?
Keep building your QA edge
Pillar guides- AI Mock Interviewpractice these questions with our AI mock interviewLive AI-powered mock interviews with rubric feedback.
- ATS Resume Reviewrun your resume through our scannerFree AI ATS scoring with rewrite suggestions.
- QA Jobs Radarsee today's openingsLive QA / SDET / automation job feed, refreshed daily.
Continue reading

Join the QA Community
Connect with fellow testers, share job leads, and get career advice.
Stop Reinventing the Wheel. Upgrade Your QA Arsenal.
Take your testing skills from beginner to Lead Engineer. Supercharge your daily workflow with our premium digital resources.
- ⚡ Ready-to-use testing strategy templates
- 🔥 Advanced API & UI automation guides
- ⏱️ Save 10+ hours a week on test planning